technologyreview | In 1886, the
British archaeologist Arthur Evans came across an ancient stone bearing a
curious set of inscriptions in an unknown language. The stone came from
the Mediterranean island of Crete, and Evans immediately traveled there
to hunt for more evidence. He quickly found numerous stones and tablets
bearing similar scripts and dated them from around 1400 BCE.
That
made the inscription one of the earliest forms of writing ever
discovered. Evans argued that its linear form was clearly derived from
rudely scratched line pictures belonging to the infancy of art, thereby
establishing its importance in the history of linguistics.
He
and others later determined that the stones and tablets were written in
two different scripts. The oldest, called Linear A, dates from between
1800 and 1400 BCE, when the island was dominated by the Bronze Age
Minoan civilization.
The other script,
Linear B, is more recent, appearing only after 1400 BCE, when the island
was conquered by Mycenaeans from the Greek mainland.
Evans
and others tried for many years to decipher the ancient scripts, but
the lost languages resisted all attempts. The problem remained unsolved
until 1953, when an amateur linguist named Michael Ventris cracked the
code for Linear B.
His
solution was built on two decisive breakthroughs. First, Ventris
conjectured that many of the repeated words in the Linear B vocabulary
were names of places on the island of Crete. That turned out to be
correct.
His
second breakthrough was to assume that the writing recorded an early
form of ancient Greek. That insight immediately allowed him to decipher
the rest of the language. In the process, Ventris showed that ancient
Greek first appeared in written form many centuries earlier than
previously thought.
Ventris’s
work was a huge achievement. But the more ancient script, Linear A, has
remained one of the great outstanding problems in linguistics to this
day.
It’s
not hard to imagine that recent advances in machine translation might
help. In just a few years, the study of linguistics has been
revolutionized by the availability of huge annotated databases, and
techniques for getting machines to learn from them. Consequently,
machine translation from one language to another has become routine. And
although it isn’t perfect, these methods have provided an entirely new
way to think about language.
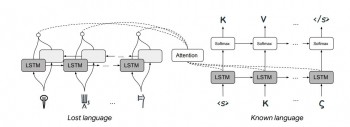
Enter
Jiaming Luo and Regina Barzilay from MIT and Yuan Cao from Google’s AI
lab in Mountain View, California. This team has developed a
machine-learning system capable of deciphering lost languages, and
they’ve demonstrated it by having it decipher Linear B—the first time
this has been done automatically. The approach they used was very
different from the standard machine translation techniques.
First
some background. The big idea behind machine translation is the
understanding that words are related to each other in similar ways,
regardless of the language involved.




0 comments:
Post a Comment