statista | While OpenAI has really risen to fame with the release of ChatGPT in
November 2022, the U.S.-based artificial intelligence research and
deployment company is about much more than its popular AI-powered
chatbot. In fact, OpenAI’s technology is already being used by hundreds
of companies around the world.
According to data published by the enterprise software platform Enterprise Apps Today,
companies in the technology and education sectors are most likely to
take advantage of OpenAI’s solutions, while business services,
manufacturing and finance are also high on the list of industries
utilizing artificial intelligence in their business processes.
Broadly
defined as “the theory and development of computer systems able to
perform tasks normally requiring human intelligence, such as visual
perception, speech recognition, decision-making, and translation between
languages” artificial intelligence (AI) can now be found in various
applications, including for example web search, natural language
translation, recommendation systems, voice recognition and autonomous
driving. In healthcare, AI can help synthesize large volumes of clinical
data to gain a holistic view of the patient, but it’s also used in
robotics for surgery, nursing, rehabilitation and orthopedics.
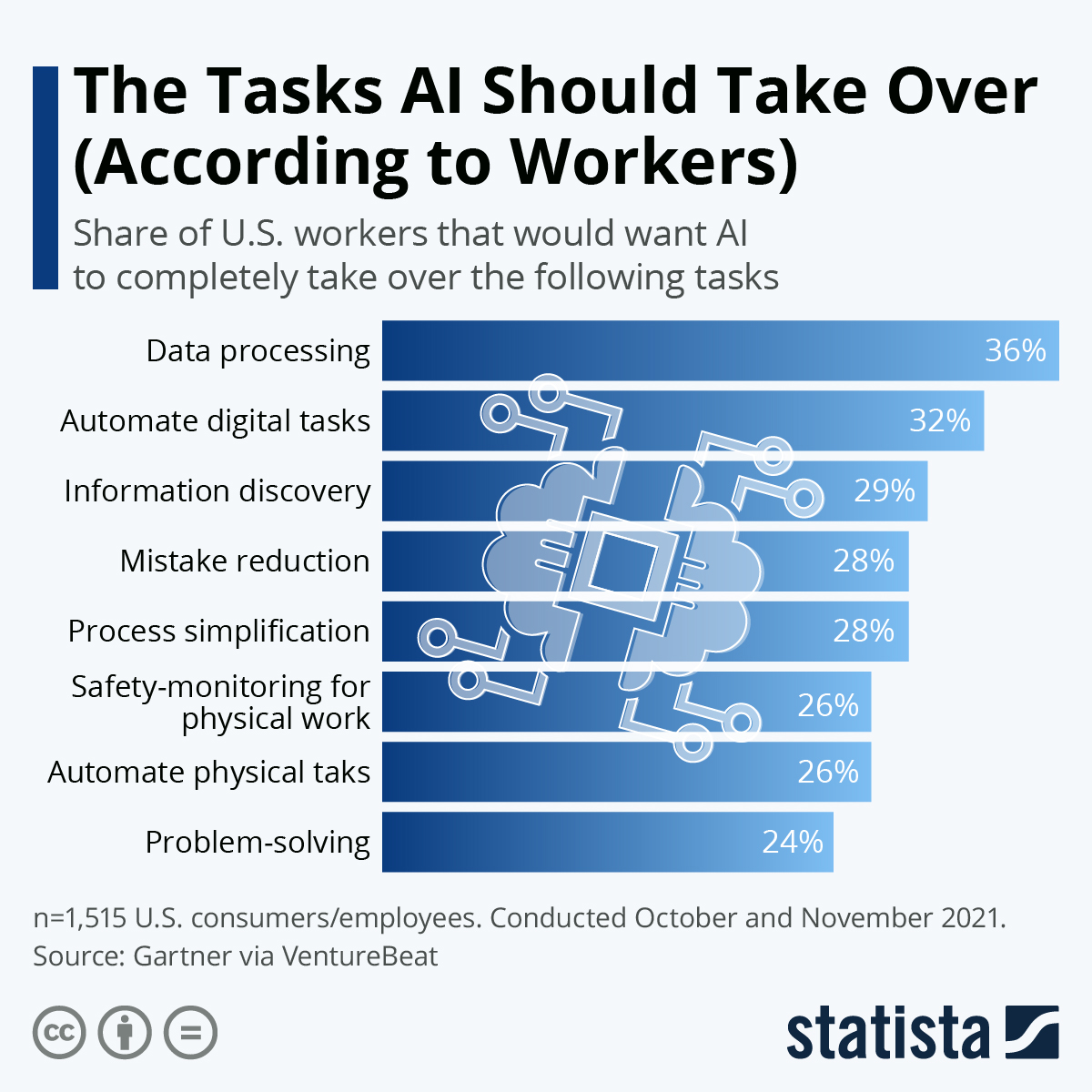
statista | While there are, especially in industries like manufacturing, legitimate fears that robots and artificial intelligence
could cost people their jobs, a lot of workers in the United States
prefer to look on the positive side, imagining which of the more
laborious of their tasks could be taken off their hands by AI.
According to a recent survey by Gartner,
70 percent of U.S. workers would like to utilize AI for their jobs to
some degree. As our infographic shows, a fair chunk of respondents also
named some tasks which they would be more than happy to give up
completely. Data processing is at the top of the list with 36 percent,
while an additional 50 percent would at least like AI to help them out
in this.
On the other side of the story, as reported by VentureBeat:
"Among survey respondents who did not want to use AI at work, privacy
and security concerns were cited as the top two reasons for declining
AI." To help convince these workers, Gartner recommends "that IT leaders
interested in using AI solutions in the workplace gain support for this
technology by demonstrating that AI is not meant to replace or take
over the workforce. Rather, it can help workers be more effective and
work on higher-value tasks."
What if, bear with me now, what if the phase 3 clinical trials for mRNA therapeutics conducted on billions of unsuspecting, hoodwinked and bamboozled humans, was a new kind of research done to yield a new depth and breadth of clinical data exceptionally useful toward breaking up logjams in clinical terminology as well as experimental sample size? Vaxxed vs. Unvaxxed the subject of long term gubmint surveillance now. To what end?
Nature | Recently,
advances in wearable technologies, data science and machine learning
have begun to transform evidence-based medicine, offering a tantalizing
glimpse into a future of next-generation ‘deep’ medicine. Despite
stunning advances in basic science and technology, clinical translations
in major areas of medicine are lagging. While the COVID-19 pandemic
exposed inherent systemic limitations of the clinical trial landscape,
it also spurred some positive changes, including new trial designs and a
shift toward a more patient-centric and intuitive evidence-generation
system. In this Perspective, I share my heuristic vision of the future
of clinical trials and evidence-based medicine.
Main
The
last 30 years have witnessed breathtaking, unparalleled advancements in
scientific research—from a better understanding of the pathophysiology
of basic disease processes and unraveling the cellular machinery at
atomic resolution to developing therapies that alter the course and
outcome of diseases in all areas of medicine. Moreover, exponential
gains in genomics, immunology, proteomics, metabolomics, gut
microbiomes, epigenetics and virology in parallel with big data science,
computational biology and artificial intelligence (AI) have propelled
these advances. In addition, the dawn of CRISPR–Cas9 technologies has
opened a tantalizing array of opportunities in personalized medicine.
Despite
these advances, their rapid translation from bench to bedside is
lagging in most areas of medicine and clinical research remains
outpaced. The drug development and clinical trial landscape continues to
be expensive for all stakeholders, with a very high failure rate. In
particular, the attrition rate for early-stage developmental
therapeutics is quite high, as more than two-thirds of compounds succumb
in the ‘valley of death’ between bench and bedside1,2.
To bring a drug successfully through all phases of drug development
into the clinic costs more than 1.5–2.5 billion dollars (refs. 3, 4).
This, combined with the inherent inefficiencies and deficiencies that
plague the healthcare system, is leading to a crisis in clinical
research. Therefore, innovative strategies are needed to engage patients
and generate the necessary evidence to propel new advances into the
clinic, so that they may improve public health. To achieve this,
traditional clinical research models should make way for avant-garde
ideas and trial designs.
Before the COVID-19 pandemic, the conduct
of clinical research had remained almost unchanged for 30 years and
some of the trial conduct norms and rules, although archaic, were
unquestioned. The pandemic exposed many of the inherent systemic
limitations in the conduct of trials5
and forced the clinical trial research enterprise to reevaluate all
processes—it has therefore disrupted, catalyzed and accelerated
innovation in this domain6,7. The lessons learned should help researchers to design and implement next-generation ‘patient-centric’ clinical trials.
Chronic diseases continue to impact millions of lives and cause major financial strain to society8,
but research is hampered by the fact that most of the data reside in
data silos. The subspecialization of the clinical profession has led to
silos within and among specialties; every major disease area seems to
work completely independently. However, the best clinical care is
provided in a multidisciplinary manner with all relevant information
available and accessible. Better clinical research should harness the
knowledge gained from each of the specialties to achieve a collaborative
model enabling multidisciplinary, high-quality care and continued
innovation in medicine. Because many disciplines in medicine view the
same diseases differently—for example, infectious disease specialists
view COVID-19 as a viral disease while cardiology experts view it as an
inflammatory one—cross-discipline approaches will need to respect the
approaches of other disciplines. Although a single model may not be
appropriate for all diseases, cross-disciplinary collaboration will make
the system more efficient to generate the best evidence.
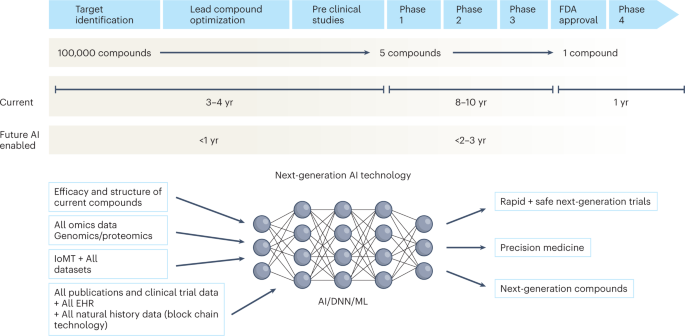
Over the
next decade, the application of machine learning, deep neural networks
and multimodal biomedical AI is poised to reinvigorate clinical research
from all angles, including drug discovery, image interpretation,
streamlining electronic health records, improving workflow and, over
time, advancing public health (Fig. 1).
In addition, innovations in wearables, sensor technology and Internet
of Medical Things (IoMT) architectures offer many opportunities (and
challenges) to acquire data9.
In this Perspective, I share my heuristic vision of the future of
clinical trials and evidence generation and deliberate on the main areas
that need improvement in the domains of clinical trial design, clinical
trial conduct and evidence generation.
Fig. 1: Timeline of drug development from the present to the future.
The
figure represents the timeline from drug discovery to first-in-human
phase 1 trials and ultimately FDA approval. Phase 4 studies occur after
FDA approval and can go on for several years. There is an urgent need to
reinvigorate clinical trials through drug discovery, interpreting
imaging, streamlining electronic health records, and improving workflow,
over time advancing public health. AI can aid in many of these aspects
in all stages of drug development. DNN, deep neural network; EHR,
electronic health records; IoMT, internet of medical things; ML, machine
learning.
Trial
design is one of the most important steps in clinical research—better
protocol designs lead to better clinical trial conduct and faster
‘go/no-go’ decisions. Moreover, losses from poorly designed, failed
trials are not only financial but also societal.
Challenges with randomized controlled trials
Randomized
controlled trials (RCTs) have been the gold standard for evidence
generation across all areas of medicine, as they allow unbiased
estimates of treatment effect without confounders. Ideally, every
medical treatment or intervention should be tested via a well-powered
and well-controlled RCT. However, conducting RCTs is not always feasible
owing to challenges in generating evidence in a timely manner, cost,
design on narrow populations precluding generalizability, ethical
barriers and the time taken to conduct these trials. By the time they
are completed and published, RCTs become quickly outdated and, in some
cases, irrelevant to the current context. In the field of cardiology
alone, 30,000 RCTs have not been completed owing to recruitment
challenges10.
Moreover, trials are being designed in isolation and within silos, with
many clinical questions remaining unanswered. Thus, traditional trial
design paradigms must adapt to contemporary rapid advances in genomics,
immunology and precision medicine11.
sciencealert | In theory, there are myriad real-world applications, including aerial
mapping for conservation and disaster relief work. But the technology
has needed to mature so that flying robots can adapt to new environments
without crashing into one another or objects, thus endangering public
safety.
Drone swarms have been tested in the past, but either in
open environments without obstacles, or with the location of those
obstacles programmed in, Enrica Soria, a roboticist at the Swiss Federal
Institute of Technology Lausanne, who was not involved in the research,
told AFP.
"This is the first time there's a swarm of drones
successfully flying outside in an unstructured environment, in the
wild," she said, adding the experiment was "impressive".
The
palm-sized robots were purpose-built, with depth cameras, altitude
sensors, and an on-board computer. The biggest advance was a clever
algorithm that incorporates collision avoidance, flight efficiency, and
coordination within the swarm.
Since these drones do not rely on any outside infrastructure, such as GPS, swarms could be used during natural disasters.
For
example, they could be sent into earthquake-hit areas to survey damage
and identify where to send help, or into buildings where it's unsafe to
send people.
It's certainly possible to use single drones in such
scenarios, but a swarm approach would be far more efficient, especially
given limited flight times.
Another possible use is having the swarm collectively lift and deliver heavy objects.
There's
also a darker side: swarms could be weaponized by militaries, just as
remote-piloted single drones are today. The Pentagon has repeatedly
expressed interest and is carrying out its own tests.
"Military
research is not shared with the rest of the world just openly, and so
it's difficult to imagine at what stage they are with their
development," said Soria.
But advances shared in scientific journals could certainly be put to military use.
Coming soon?
The
Chinese team tested their drones in different scenarios – swarming
through the bamboo forest, avoiding other drones in a high-traffic
experiment, and having the robots follow a person's lead.
"Our work was inspired by birds that fly smoothly in a free swarm through even very dense woods," wrote Zhou in a blog post.
The challenge, he said, was balancing competing demands: the
need for small, lightweight machines, but with high-computational power,
and plotting safe trajectories without greatly prolonging flight time.
thedrive | China
looks to have launched an odd mini-aircraft carrier of sorts that is
intended to launch and recover small aerial drones earlier this year. A
model of this catamaran vessel appeared at this year's Zhuhai Airshow,
where it was ostensibly described as a platform for mimicking enemy
"electronic" systems during training exercises. This ship will be able
to simulate hostile drone swarms, along with other kinds of threats,
such as high-volume anti-ship missile strikes and distributed electronic warfare attacks. It also reflects the Chinese military's interest in operational swarming capabilities, and especially in the maritime domain.
Earlier this week, Twitter user @HenriKenhmann, who runs the website East Pendulum, was able to find a picture online
of the ship during an apparent launch ceremony in May. The photograph
shows an unusual cartoon shark motif painted on the outside of one of
the ship's twin hulls, very similar to what was seen on the model at
Zhuhai. This model has received more recent attention as it was
displayed alongside one depicting a rail-based training aid that has
also turned out to be in operational use, as you can read more about here.
There was a small sign next to the model at Zhuhai with descriptions of
the ship in Chinese and English. Available pictures of the sign do not
provide a clear view of all of the English text, but part of it reads
"Multifunctional Integrated Electronic Blue Army System." In Chinese
military parlance, mock opponents in training exercises are referred to
as the "Blue Army."
This is in direct contrast to how the U.S. military and other western
armed forces describe generic simulated enemies as the "Red Force."
Based
on this description, and from what we can see of the ship's design and
that of the drones on its deck, it's not hard to imagine how it might be
employed in maritime exercises both far out to sea and in littoral
areas. For realistic training against swarms, it would be necessary to
sortie lots of drones at once.
Beyond that, the unmanned helicopters could pump out signals
reflecting the signatures of various kinds of missiles, or even just
waves of manned or unmanned aircraft. The rotary-wing drones would be
fitted with electronic warfare systems to carry out electronic attacks,
as well. All of this would provide a relatively low-cost way to
simulate swarms, along with other kinds of aerial threats during drills,
and do so across a broad area.
The
large open decks on the ship in front of and behind the superstructure
might provide room for the addition of other capabilities. Catapults or
static launchers for fixed-wing drones, including those designed specifically as targets,
as well as recovery systems, could be installed in those spaces to
expand the kinds of threats the vessel would be to simulate.
mit | Materials called perovskites are widely heralded as a likely
replacement for silicon as the material of choice for solar cells, but
their greatest drawback is their tendency to degrade relatively rapidly.
Over recent years, the usable lifetime of perovskite-based cells has
gradually improved from minutes to months, but it still lags far behind
the decades expected from silicon, the material currently used for
virtually all commercial solar panels.
Now, an international interdisciplinary team led by MIT has come up
with a new approach to narrowing the search for the best candidates for
long-lasting perovskite formulations, out of a vast number of potential
combinations. Already, their system has zeroed in on one composition
that in the lab has improved on existing versions more than tenfold.
Even under real-world conditions at full solar cell level, beyond just a
small sample in a lab, this type of perovskite has performed three
times better than the state-of-the-art formulations.
The findings appear in the journal Matter, in a paper by MIT
research scientist Shijing Sun, MIT professors, Moungi Bawendi, John
Fisher, and Tonio Buonassisi, who is also a principal investigator at
the Singapore-MIT Alliance for Research and Technology (SMART), and 16
others from MIT, Germany, Singapore, Colorado, and New York.
Perovskites are a broad class of materials characterized by the way
atoms are arranged in their layered crystal lattice. These layers,
described by convention as A, B, and X, can each consist of a variety of
different atoms or compounds. So, searching through the entire universe
of such combinations to find the best candidates to meet specific goals
— longevity, efficiency, manufacturability, and availability of source
materials — is a slow and painstaking process, and largely one without
any map for guidance.
“If you consider even just three elements, the most common ones in
perovskites that people sub in and out are on the A site of the
perovskite crystal structure,” which can each easily be varied by
1-percent increments in their relative composition, Buonassisi says.
“The number of steps becomes just preposterous. It becomes very, very
large” and thus impractical to search through systematically. Each step
involves the complex synthesis process of creating a new material and
then testing its degradation, which even under accelerated aging
conditions is a time-consuming process.
The key to the team’s success is what they describe as a data fusion
approach. This iterative method uses an automated system to guide the
production and testing of a variety of formulations, then uses machine
learning to go through the results of those tests, combined again with
first-principles physical modeling, to guide the next round of
experiments. The system keeps repeating that process, refining the
results each time.
Buonassisi likes to compare the vast realm of possible compositions
to an ocean, and he says most researchers have stayed very close to the
shores of known formulations that have achieved high efficiencies, for
example, by tinkering just slightly with those atomic configurations.
However, “once in a while, somebody makes a mistake or has a stroke of
genius and departs from that and lands somewhere else in composition
space, and hey, it works better! A happy bit of serendipity, and then
everybody moves over there” in their research. “But it's not usually a
structured thought process.”
This new approach, he says, provides a way to explore far offshore
areas in search of better properties, in a more systematic and efficient
way. In their work so far, by synthesizing and testing less than 2
percent of the possible combinations among three components, the
researchers were able to zero in on what seems to be the most durable
formulation of a perovskite solar cell material found to date.
mit | In recent years, research efforts such as the Materials Genome Initiative and the Materials Project
have produced a wealth of computational tools for designing new
materials useful for a range of applications, from energy and
electronics to aeronautics and civil engineering.
But developing
processes for producing those materials has continued to depend on a
combination of experience, intuition, and manual literature reviews.
A
team of researchers at MIT, the University of Massachusetts at Amherst,
and the University of California at Berkeley hope to close that
materials-science automation gap, with a new artificial-intelligence
system that would pore through research papers to deduce “recipes” for
producing particular materials.
“Computational materials
scientists have made a lot of progress in the ‘what’ to make — what
material to design based on desired properties,” says Elsa Olivetti, the
Atlantic Richfield Assistant Professor of Energy Studies in MIT’s
Department of Materials Science and Engineering (DMSE). “But because of
that success, the bottleneck has shifted to, ‘Okay, now how do I make
it?’”
The researchers envision a database that contains materials
recipes extracted from millions of papers. Scientists and engineers
could enter the name of a target material and any other criteria —
precursor materials, reaction conditions, fabrication processes — and
pull up suggested recipes.
As a step toward realizing that vision,
Olivetti and her colleagues have developed a machine-learning system
that can analyze a research paper, deduce which of its paragraphs
contain materials recipes, and classify the words in those paragraphs
according to their roles within the recipes: names of target materials,
numeric quantities, names of pieces of equipment, operating conditions,
descriptive adjectives, and the like.
In a paper appearing in the latest issue of the journal Chemistry of Materials,
they also demonstrate that a machine-learning system can analyze the
extracted data to infer general characteristics of classes of materials —
such as the different temperature ranges that their synthesis requires —
or particular characteristics of individual materials — such as the
different physical forms they will take when their fabrication
conditions vary.
wired |The repercussions of
Gebru’s termination quickly radiated out from her team to the rest of
Google and, beyond that, to the entire discipline of AI fairness
research.
Some Google employees, including David
Baker, a director who’d been at the company for 16 years, publicly quit
over its treatment of Gebru. Google’s research department was riven by
mistrust and rumors about what happened and what might happen next. Even
people who believed Gebru had behaved in ways unbecoming of a corporate
researcher saw Google’s response as ham-handed. Some researchers feared
their work would now be policed more closely. One of them, Nicholas
Carlini, sent a long internal email complaining of changes that company
lawyers made to another paper involving large language models, published
after Gebru was fired, likening the intervention to “Big Brother
stepping in.” The changes downplayed the problems the paper reported and
removed references to Google’s own technology, the email said.
Soon
after, Google rolled out its response to the roiling scandal and
sketched out a more locked-down future for in-house research probing
AI’s power. Marian Croak, the executive who had shown interest in
Gebru’s work, was given the task of consolidating the various teams
working on what the company called responsible AI, including Mitchell
and Gebru’s. Dean sent around an email announcing that a review of
Gebru’s ouster had concluded; he was sorry, he said, that the company
had not “handled this situation with more sensitivity.”
Dean
also announced that progress on improving workforce diversity would now
be considered in top executives’ performance reviews—perhaps quietly
conceding Gebru’s assertion that leaders were not held accountable for
their poor showing on this count. And he informed researchers that they
would be given firmer guidance on “Google’s research goals and
priorities.” A Google source later explained that this meant future
projects touching on sensitive or commercial topics would require more
input from in-house legal experts, product teams, and others within
Google who had relevant expertise. The outlook for open-minded,
independent research on ethical AI appeared gloomy. Google claimed that
it still had hundreds of people working on responsible AI, and that it
would expand those teams; the company painted Gebru and Mitchell’s group
as a tiny and relatively unimportant cog in a big machine. But others
at Google said the Ethical AI leaders and their frank feedback would be
missed. “For me, it’s the most critical voices that are the most
important and where I have learned the most,” says one person who worked
on product changes with Gebru and Mitchell’s input. Bengio, the women’s
manager, turned his back on 14 years of working on AI at Google and
quit to join Apple.
Outside of Google, nine
Democrats in Congress wrote to Pichai questioning his commitment to
preventing AI’s harms. Mitchell had at one point tried to save the
“Stochastic Parrots” paper by telling executives that publishing it
would bolster arguments that the company was capable of self-policing.
Quashing it was now undermining those arguments.
Some
academics announced that they had backed away from company events or
funding. The fairness and technology conference’s organizers stripped
Google of its status as a sponsor of the event. Luke Stark, who studies
the social impacts of AI at the University of Western Ontario, turned
down a $60,000 grant from Google in protest of its treatment of the
Ethical AI team. When he applied for the money in December 2020, he had
considered the team a “strong example” of how corporate researchers
could do powerful work. Now he wanted nothing to do with Google.
Tensions built into the field of AI ethics, he saw, were beginning to
cause fractures.
“The big tech companies tried to
steal a march on regulators and public criticism by embracing the idea
of AI ethics,” Stark says. But as the research matured, it raised bigger
questions. “Companies became less able to coexist with internal
critical research,” he says. One person who runs an ethical AI team at
another tech company agrees. “Google and most places did not count on
the field becoming what it did.”
To some, the
drama at Google suggested that researchers on corporate payrolls should
be subject to different rules than those from institutions not seeking
to profit from AI. In April, some founding editors of a new journal of
AI ethics published a paper calling for industry researchers to disclose
who vetted their work and how, and for whistle-blowing mechanisms to be
set up inside corporate labs. “We had been trying to poke on this issue
already, but when Timnit got fired it catapulted into a more mainstream
conversation,” says Savannah Thais, a researcher at Princeton on the
journal’s board who contributed to the paper. “Now a lot more people are
questioning: Is it possible to do good ethics research in a corporate
AI setting?”
If that mindset takes hold, in-house
ethical AI research may forever be held in suspicion—much the way
industrial research on pollution is viewed by environmental scientists.
Jeff Dean admitted in a May interview with CNET that the company had
suffered a real “reputational hit” among people interested in AI ethics
work. The rest of the interview dealt mainly with promoting Google’s
annual developer conference, where it was soon announced that large
language models, the subject of Gebru’s fateful critique, would play a
more central role in Google search and the company’s voice assistant.
Meredith Whittaker, faculty director of New York University’s AI Now
Institute, predicts that there will be a clearer split between work done
at institutions like her own and work done inside tech companies. “What
Google just said to anyone who wants to do this critical research is,
‘We’re not going to tolerate it,’” she says. (Whittaker herself once
worked at Google, where she clashed with management over AI ethics and
the Maven Pentagon contract before leaving in 2019.)
Any
such divide is unlikely to be neat, given how the field of AI ethics
sprouted in a tech industry hothouse. The community is still small, and
jobs outside big companies are sparser and much less well paid,
particularly for candidates without computer science PhDs. That’s in
part because AI ethics straddles the established boundaries of academic
departments. Government and philanthropic funding is no match for
corporate purses, and few institutions can rustle up the data and
computing power needed to match work from companies like Google.
For
Gebru and her fellow travelers, the past five years have been
vertiginous. For a time, the period seemed revolutionary: Tech companies
were proactively exploring flaws in AI, their latest moneymaking
marvel—a sharp contrast to how they’d faced up to problems like spam and
social network moderation only after coming under external pressure.
But now it appeared that not much had changed after all, even if many
individuals had good intentions.
Inioluwa Deborah
Raji, whom Gebru escorted to Black in AI in 2017, and who now works as a
fellow at the Mozilla Foundation, says that Google’s treatment of its
own researchers demands a permanent shift in perceptions. “There was
this hope that some level of self-regulation could have happened at
these tech companies,” Raji says. “Everyone’s now aware that the true
accountability needs to come from the outside—if you’re on the inside,
there’s a limit to how much you can protect people.”
Gebru,
who recently returned home after her unexpectedly eventful road trip,
has come to a similar conclusion. She’s raising money to launch an
independent research institute modeled on her work on Google’s Ethical
AI team and her experience in Black in AI. “We need more support for
external work so that the choice is not ‘Do I get paid by the DOD or by
Google?’” she says.
Gebru has had offers, but she
can’t imagine working within the industry anytime in the near future.
She’s been thinking back to conversations she’d had with a friend who
warned her not to join Google, saying it was harmful to women and
impossible to change. Gebru had disagreed, claiming she could nudge
things, just a little, toward a more beneficial path. “I kept on arguing
with her,” Gebru says. Now, she says, she concedes the point.
Guardian |Kate Crawford studies the social and political implications of artificial intelligence. She is a research
professor of communication and science and technology studies at the
University of Southern California and a senior principal researcher at Microsoft Research. Her new book, Atlas of AI, looks at what it takes to make AI and what’s at stake as it reshapes our world.
You’ve written a book critical of AI but you work for a company that is among the leaders in its deployment. How do you square that circle? I
work in the research wing of Microsoft, which is a distinct
organisation, separate from product development. Unusually, over its
30-year history, it has hired social scientists to look critically at
how technologies are being built. Being on the inside, we are often able
to see downsides early before systems are widely deployed. My book did
not go through any pre-publication review – Microsoft Research does not
require that – and my lab leaders support asking hard questions, even if
the answers involve a critical assessment of current technological
practices.
What’s the aim of the book? We
are commonly presented with this vision of AI that is abstract and
immaterial. I wanted to show how AI is made in a wider sense – its
natural resource costs, its labour processes, and its classificatory
logics. To observe that in action I went to locations including mines to
see the extraction necessary from the Earth’s crust and an Amazon
fulfilment centre to see the physical and psychological toll on workers
of being under an algorithmic management system. My hope is that, by
showing how AI systems work – by laying bare the structures of
production and the material realities – we will have a more accurate
account of the impacts, and it will invite more people into the
conversation. These systems are being rolled out across a multitude of
sectors without strong regulation, consent or democratic debate.
What should people know about how AI products are made? We
aren’t used to thinking about these systems in terms of the
environmental costs. But saying, “Hey, Alexa, order me some toilet
rolls,” invokes into being this chain of extraction, which goes all
around the planet… We’ve got a long way to go before this is green
technology. Also, systems might seem automated but when we pull away the
curtain we see large amounts of low paid labour, everything from crowd
work categorising data to the never-ending toil of shuffling Amazon
boxes. AI is neither artificial nor intelligent. It is made from natural
resources and it is people who are performing the tasks to make the
systems appear autonomous.
Problems of bias have been well documented in AI technology. Can more data solve that? Bias
is too narrow a term for the sorts of problems we’re talking about.
Time and again, we see these systems producing errors – women offered
less credit by credit-worthiness algorithms, black faces mislabelled –
and the response has been: “We just need more data.” But I’ve tried to
look at these deeper logics of classification and you start to see forms
of discrimination, not just when systems are applied, but in how they
are built and trained to see the world. Training datasets used for
machine learning software thatcasually categorise
people into just one of two genders; that label people according to
their skin colour into one of five racial categories, and which attempt,
based on how people look, to assign moral or ethical character. The
idea that you can make these determinations based on appearance has a
dark past and unfortunately the politics of classification has become
baked into the substrates of AI.
and these workers don't have to stop and pee in a bottle....,
bostondynamics | Robotic navigation of complex subterranean settings is important for
a wide variety of applications ranging from mining and planetary cave
exploration to search and rescue and first response. In many cases,
these domains are too high-risk for personnel to enter, but they
introduce a lot of challenges and hazards for robotic systems, testing
the limits of their mobility, autonomy, perception, and communications.
The DARPA Subterranean (SubT) Challenge seeks novel approaches to
rapidly map, navigate, and search fully unknown underground environments
during time-constrained operations and/or disaster response scenarios.
In the most recent competition, called the Urban Circuit,
teams raced against one another in an unfinished power plant in Elma,
Washington. Each team's robots searched for a set of
spatially-distributed objects, earning a point for finding and precisely
localizing each object.
Whether robots are exploring caves on other planets or disaster areas
here on Earth, autonomy enables them to navigate extreme environments
without human guidance or access to GPS.
The Solution
TEAM CoSTAR,
which stands for Collaborative SubTerranean Autonomous Robots, relies
on a team of heterogeneous autonomous robots that can roll, walk or fly,
depending on what they encounter. Robots autonomously explore and
create a 3D map of the subsurface environment. CoSTAR is a collaboration
between NASA’s JPL, MIT, Caltech, KAIST, LTU, and industry partners.
“CoSTAR develops a holistic autonomy, perception, and communication
framework called NeBula (Networked Belief-aware Perceptual Autonomy),
enabling various rolling and flying robots to autonomously explore
unknown environments. In the second year of the project, we aimed at
extending our autonomy framework to explore underground structures
including multiple levels and mobility stressing-features. We were
looking into expanding the locomotion capabilities of our robotic team
to support this level of autonomy. Spot was the perfect choice for us
due to its size, agility, and capabilities.
We got the Spot robot only about 2 months before the competition.
Thanks to the modularity of the NeBula and great support from Boston
Dynamics, the team was able to integrate our autonomy framework NeBula
on Spot in several weeks. It was a risky and aggressive change in our
plans very close to the competition, but it paid off and the integrated
NeBula-on-Spot framework demonstrated an amazing performance in the
competition.” said CoSTAR's team lead Ali Agha of JPL. "The
NeBula-powered Spots were able to explore 100s of meters autonomously in
less than 60 minutes, negotiate mobility-stressing terrains and
obstacles, and go up and down stairs, exploring multiple levels."
The Results
Performance of the NeBula-enabled Spots alongside CoSTARs roving and
flying robots led to the first place in the urban round of competition
for team CoSTAR. For more information about Team CoSTAR's win, see:
trust | I drove for
Amazon from December 2019 until March of 2021, and I want to shed light
on the work environment and the way the world's largest online retailer
treats its employees. I want to show support for all the people I worked
with and drove with, and
with those who wear the blue vest across the nation. I support the
driver walk-out on Easter Sunday. It's time to show Amazon that drivers
are people who deserve better, and not machines who don't need a
bathroom break!
When Vic started delivering packages
for Amazon in 2019, he enjoyed it - the work was physical, he liked the
autonomy, and it let him explore new neighborhoods in Denver, Colorado.
But Vic, who asked to be referred to by his first name for fear of
retaliation, did not like the sensation that he was constantly under
surveillance.
At first, it was Amazon’s “Mentor” app that constantly monitored his
driving, phone use and location, generating a score for bosses to
evaluate his performance on the road.
“If we went over a bump, the phone would rattle, the Mentor app would
log that I used the phone while driving, and boom, I’d get docked,” he
said.
Then, Amazon started asking him to post “selfies” before each shift on Amazon Flex, another app he had to install.
“I had already logged in with my keycard at the beginning of the shift, and now they want a photo? It was too much," he said.
The final indignity, he said, was Amazon's decision to install a
four-lens, AI-powered camera in delivery vehicles that would record and
analyse his face and body the entire shift.
This month, Vic put in his two-week notice and quit, ahead of a March
23 deadline for all workers at his Denver dispatch location to sign
release forms authorising Amazon to film them and collect and store
their biometric information.
“It was both a privacy violation, and a breach of trust,” he said. “And I was not going to stand for it.”
The camera systems, made by U.S.-based firm Netradyne, are part of a
nationwide effort by Amazon to address concerns over accidents involving
its increasingly ubiquitous delivery vans.
Amazon did not respond to a request for comment, but has previously
told the Thomson Reuters Foundation that access to the footage was
limited, and video would only be uploaded after an unsafe driving
incident was detected.
Albert Fox Cahn, who runs the Surveillance Technology Oversight
Project - a privacy organisation - said the Amazon cameras were part of a
worrying, new trend.
"As cameras get cheaper and artificial intelligence becomes more
powerful, these invasive tracking systems are increasingly the norm," he
said.
newsweek |In this extract from When Google Met WikiLeaks Assange describes his encounter with Schmidt and how he came to conclude that it was far from an innocent exchange of views.
Eric Schmidt is an influential figure, even among the parade of
powerful characters with whom I have had to cross paths since I founded
WikiLeaks. In mid-May 2011 I was under house arrest in rural Norfolk,
England, about three hours' drive northeast of London. The crackdown
against our work was in full swing and every wasted moment seemed like
an eternity. It was hard to get my attention.
But when my
colleague Joseph Farrell told me the executive chairman of Google wanted
to make an appointment with me, I was listening.
In some ways the higher echelons of Google seemed more distant and
obscure to me than the halls of Washington. We had been locking horns
with senior U.S. officials for years by that point. The mystique had
worn off. But the power centers growing up in Silicon Valley were still
opaque and I was suddenly conscious of an opportunity to understand and
influence what was becoming the most influential company on earth.
Schmidt had taken over as CEO of Google in 2001 and built it into an
empire.
I was intrigued that the mountain would come to Muhammad. But it was
not until well after Schmidt and his companions had been and gone that I
came to understand who had really visited me.
The stated reason
for the visit was a book. Schmidt was penning a treatise with Jared
Cohen, the director of Google Ideas, an outfit that describes itself as
Google's in-house "think/do tank."
I knew little else about Cohen
at the time. In fact, Cohen had moved to Google from the U.S. State
Department in 2010. He had been a fast-talking "Generation Y" ideas man
at State under two U.S. administrations, a courtier from the world of
policy think tanks and institutes, poached in his early twenties.
He
became a senior advisor for Secretaries of State Rice and Clinton. At
State, on the Policy Planning Staff, Cohen was soon christened "Condi's
party-starter," channeling buzzwords from Silicon Valley into U.S.
policy circles and producing delightful rhetorical concoctions such as
"Public Diplomacy 2.0." On his Council on Foreign Relations adjunct staff page he listed his expertise as "terrorism; radicalization; impact of connection technologies on 21st century statecraft; Iran."
It
was Cohen who, while he was still at the Department of State, was said
to have emailed Twitter CEO Jack Dorsey to delay scheduled maintenance
in order to assist the aborted 2009 uprising in Iran. His documented
love affair with Google began the same year when he befriended Eric
Schmidt as they together surveyed the post-occupation wreckage of
Baghdad. Just months later, Schmidt re-created Cohen's natural habitat
within Google itself by engineering a "think/do tank" based in New York
and appointing Cohen as its head. Google Ideas was born.
Later that year two co-wrote a policy piece
for the Council on Foreign Relations' journal Foreign Affairs, praising
the reformative potential of Silicon Valley technologies as an
instrument of U.S. foreign policy. Describing what they called
"coalitions of the connected," Schmidt and Cohen claimed that:
Democratic states that have built
coalitions of their militaries have the capacity to do the same with
their connection technologies.…
They offer a new way to exercise the duty to protect citizens around the world [emphasis added].
theverge | Google has fired Margaret Mitchell, co-lead of the
ethical AI team, after she used an automated script to look through her
emails in order to find evidence of discrimination against her coworker
Timnit Gebru. The news was first reported by Axios.
Mitchell’s firing comes one day after Google announced a reorganization to its AI teams
working on ethics and fairness. Marian Croak, a vice president in the
engineering organization, is now leading “a new center of expertise on
responsible AI within Google Research,” according to a blog post.
Mitchell joined Google in 2016 as a senior research
scientist, according to her LinkedIn. Two years later, she helped start
the ethical AI team alongside Gebru, a renowned researcher known for her
workon bias in facial recognition technology.
In December 2020, Mitchell and Gebru were working on a
paper about the dangers of large language processing models when Megan
Kacholia, vice president of Google Brain, asked that the article be
retracted. Gebru pushed back, saying the company needed to be more open
about why the research wasn’t acceptable. Shortly afterwards, she was fired, though Google characterized her departure as a resignation.
After Gebru’s termination, Mitchell became openly
critical of Google executives, including Google AI division head Jeff
Dean and Google CEO Sundar Pichai. In January, she lost her corporate
email access after Google began investigating her activity.
“After conducting a review of this manager’s conduct, we
confirmed that there were multiple violations of our code of conduct, as
well as of our security policies, which included the exfiltration of
confidential business-sensitive documents and private data of other
employees,” Google said in a statement to Axios about Mitchell’s firing.
technologyreview | The first thing to understand here is that neural networks are
fundamentally function approximators. (Say what?) When they’re training
on a data set of paired inputs and outputs, they’re actually calculating
the function, or series of math operations, that will transpose one
into the other. Think about building a cat detector. You’re training the
neural network by feeding it lots of images of cats and things that are
not cats (the inputs) and labeling each group with a 1 or 0,
respectively (the outputs). The neural network then looks for the best
function that can convert each image of a cat into a 1 and each image of
everything else into a 0. That’s how it can look at a new image and
tell you whether or not it’s a cat. It’s using the function it found to
calculate its answer—and if its training was good, it’ll get it right
most of the time.
Conveniently, this function approximation
process is what we need to solve a PDE. We’re ultimately trying to find a
function that best describes, say, the motion of air particles over
physical space and time.
Now here’s the crux of the paper.
Neural networks are usually trained to approximate functions between
inputs and outputs defined in Euclidean space, your classic graph with
x, y, and z axes. But this time, the researchers decided to define the
inputs and outputs in Fourier space, which is a special type of graph
for plotting wave frequencies. The intuition that they drew upon from
work in other fields is that something like the motion of air can
actually be described as a combination of wave frequencies, says Anima
Anandkumar, a Caltech professor who oversaw the research alongside her
colleagues, professors Andrew Stuart and Kaushik Bhattacharya. The
general direction of the wind at a macro level is like a low frequency
with very long, lethargic waves, while the little eddies that form at
the micro level are like high frequencies with very short and rapid
ones.
Why does this matter? Because it’s far easier to
approximate a Fourier function in Fourier space than to wrangle with
PDEs in Euclidean space, which greatly simplifies the neural network’s
job. Cue major accuracy and efficiency gains: in addition to its huge
speed advantage over traditional methods, their technique achieves a 30%
lower error rate when solving Navier-Stokes than previous deep-learning
methods.
The whole thing is extremely clever, and also makes
the method more generalizable. Previous deep-learning methods had to be
trained separately for every type of fluid, whereas this one only needs
to be trained once to handle all of them, as confirmed by the
researchers’ experiments. Though they haven’t yet tried extending this
to other examples, it should also be able to handle every earth
composition when solving PDEs related to seismic activity, or every
material type when solving PDEs related to thermal conductivity.
Gebru Called Into Question Google's Reputation Based on the leaked email, Gebru's research says that machine learning at Google (the core of Google's products) creates more harm than good. Somebody finally figured out there that if she is effective in her role, she would be calling into question the ethical standing of Google's core products. If a corporation does ethics
research but is unwilling to publicize anything that could be considered
critical, then it's not ethics research, it's just peer-reviewed
public relations.
Google miscalculated with Gebru. They thought her comfy paycheck would buy her reputational complicity. Like a typical diversity hire at Corporation X, Gebru was supposed to function as a token figleaf and glad hander among snowflakes who might otherwise ask hard questions. Now Google couldn't just tell her that she was hired to be the good AI house negroe, could they?
Google wants the good narrative of "internal ethics research being done" They want to shape that narrative and message about all of "the improvements we can make" whatever it takes so that questions about their products don't effect their bottom line. With internal ethics research you have access to exponentially more data (directly and indirectly, the latter because
you know who to talk to and can do so) than any poor academic researcher.
The
field has AI Ethics research teams working on important problems (to
the community as a whole). These teams are well funded, sometimes with
huge resources. Now to get the best out of this system, the researchers just need
to avoid conflicts with the company core business. In the case of Gebru's paper, it could have been reframed in a way that would please Google, without sacrificing its
scientific merit. Shaping the narrative is extremely important in politics, business, and ethics.
And Openly Flouted Managerial Authoriteh Some are critical if machine learning SVP Jeff Dean for rejecting her submission because of bad "literature review", saying that internal review is supposed to check for "disclosure of sensitive material" only.
Not only are they wrong about the ultimate purpose of internal review processes, they also missed the point of the rejection. It was never about "literature review", but instead about Google's reputation. Take another look at Dean's response email.
It ignored too much relevant research — for example, it talked about the environmental impact of large models, but disregarded subsequent research showing much greater efficiencies. Similarly, it raised concerns about bias in language models, but didn’t take into account recent research to mitigate these issues. Google is the inventor of the current market dominating language models. Who does more neural network training using larger data sets than Google?
This is how and why Gebru's paper argues that Google creates more harm than good. Would you approve such a paper, as is? This is being kept to the paper and the email to the internal snowflake list - we don't need to examine her intention to sue Google last year, or calling on colleagues to enlist third-party organizations to put more pressure on Google.
Put yourself in Google's cloven-hooved shoes.
Gebru: Here's my paper in which I call out the environmental impact of large models and raise concerns about bias in the language data sets. Tomorrow is the deadline, please review and approve it.
Google: Hold on, this makes us look very bad! You have to revise the paper. We know that large models are not good for the environment, but we have also been doing research to achieve much greater efficiencies. We are also aware of bias in the language models that we are using in production, but we are also proposing solutions to that. You should include those works as well.
Gebru: Give me the names of every single person who reviewed my paper otherwise I'll resign. Throw on top of this the fact that she told hundreds of people in the org to cease important work because she had some disagreements with leadership.
Google: You're Fired!!! Get Out - We'll Pack Your Shit And Mail It To You!!!!
Scientific American
featured an article by LANL physicist and neuroscientist Garrett
Kenyon, who wrote that one of the
“distinguishing features of machines is that they don’t need to sleep,
unlike humans and any other creature with a central nervous system,” but
someday “your toaster might need a nap from time to time, as may your
car, fridge and anything else that is revolutionized
with the advent of practical artificial intelligence technologies.”
NOPE!
What Machine Learning (So-Called AI) Really Is
The vast majority of advances in the field of "machine learning"
(so-called AI) stem from a single technique (neural networks with back
propagation) combined with dramatic leaps in processing power.
Back-propagation is the essence of neural net "training". It is the
method of fine-tuning the weights of a neural net based on the error
rate obtained in the previous iteration. Proper tuning of the weights
allows you to reduce error rates and to make
the model reliable by increasing its generalization.
The learning mechanism is very generic, which makes it broadly
applicable to almost everything, but also makes it ‘dumb’ in the sense
that it doesn’t understand anything about context or have the ability to
abstract notable features and form models.
Humans do this non-dumb "abstraction from feature and form context"
stuff - all the time. It’s what enables us to do higher reasoning
without a whole data center worth of processing power.
Google and other big-tech/big-data companies are interested in
neural networks with back propagation from a short term business
perspective. There's still a lot to be gained from taking the existing
technique and wringing every drop of commercial potential
out of it.
Google is engineering first and researching second, if at all. That
means that any advances they come up with tend to skew towards
heuristics and implementation, rather than untangling the theory.
I’ve been struck by how many so-called ‘research’ papers in AI boil
down to “you should do this because it seems to work better than the
alternatives” with no real attempt to explain why.
technologyreview | The paper, which builds off the work of other researchers, presents the
history of natural-language processing, an overview of four main risks
of large language models, and suggestions for further research. Since
the conflict with Google seems to be over the risks, we’ve focused on
summarizing those here.
Environmental and financial costs
Training large AI models
consumes a lot of computer processing power, and hence a lot of
electricity. Gebru and her coauthors refer to a 2019 paper from Emma
Strubell and her collaborators on the carbon emissions and financial costs
of large language models. It found that their energy consumption and
carbon footprint have been exploding since 2017, as models have been fed
more and more data.
Strubell’s study found that one language model with a particular type of
“neural architecture search” (NAS) method would have produced the
equivalent of 626,155 pounds (284 metric tons) of carbon dioxide—about
the lifetime output of five average American cars. A version of Google’s
language model, BERT, which underpins the company’s search engine,
produced 1,438 pounds of CO2 equivalent in Strubell’s estimate—nearly
the same as a roundtrip flight between New York City and San Francisco.
Gebru’s draft paper points out that the sheer resources required to
build and sustain such large AI models means they tend to benefit
wealthy organizations, while climate change hits marginalized
communities hardest. “It is past time for researchers to prioritize
energy efficiency and cost to reduce negative environmental impact and
inequitable access to resources,” they write.
Massive data, inscrutable models
Large
language models are also trained on exponentially increasing amounts of
text. This means researchers have sought to collect all the data they
can from the internet, so there's a risk that racist, sexist, and
otherwise abusive language ends up in the training data.
An AI
model taught to view racist language as normal is obviously bad. The
researchers, though, point out a couple of more subtle problems. One is
that shifts in language play an important role in social change; the
MeToo and Black Lives Matter movements, for example, have tried to
establish a new anti-sexist and anti-racist vocabulary. An AI model
trained on vast swaths of the internet won’t be attuned to the nuances
of this vocabulary and won’t produce or interpret language in line with
these new cultural norms.
It will also fail to capture the
language and the norms of countries and peoples that have less access to
the internet and thus a smaller linguistic footprint online. The result
is that AI-generated language will be homogenized, reflecting the
practices of the richest countries and communities.
Moreover,
because the training datasets are so large, it’s hard to audit them to
check for these embedded biases. “A methodology that relies on datasets
too large to document is therefore inherently risky,” the researchers
conclude. “While documentation allows for potential accountability,
[...] undocumented training data perpetuates harm without recourse.”
Research opportunity costs
The
researchers summarize the third challenge as the risk of “misdirected
research effort.” Though most AI researchers acknowledge that large
language models don’t actually understand language and are merely excellent at manipulating
it, Big Tech can make money from models that manipulate language more
accurately, so it keeps investing in them. “This research effort brings
with it an opportunity cost,” Gebru and her colleagues write. Not as
much effort goes into working on AI models that might achieve
understanding, or that achieve good results with smaller, more carefully
curated datasets (and thus also use less energy).
Illusions of meaning
The
final problem with large language models, the researchers say, is that
because they’re so good at mimicking real human language, it’s easy to
use them to fool people. There have been a few high-profile cases, such
as the college student who churned out AI-generated self-help and productivity advice on a blog, which went viral.
The
dangers are obvious: AI models could be used to generate misinformation
about an election or the covid-19 pandemic, for instance. They can also
go wrong inadvertently when used for machine translation. The
researchers bring up an example: In 2017, Facebook mistranslated a Palestinian man’s post, which said “good morning” in Arabic, as “attack them” in Hebrew, leading to his arrest.
thelastamericanvagabond |Last year, a U.S. government body
dedicated to examining how artificial intelligence can “address the
national security and defense needs of the United States” discussed in
detail the “structural” changes that the American economy and society
must undergo in order to ensure a technological advantage over China,
according to a recent document acquired through a FOIA request.
This document suggests that the U.S. follow China’s lead and even
surpass them in many aspects related to AI-driven technologies,
particularly their use of mass surveillance. This perspective clearly
clashes with the public rhetoric of prominent U.S. government officials
and politicians on China, who have labeled the Chinese government’s
technology investments and export of its surveillance systems and other
technologies as a major “threat” to Americans’ “way of life.”
In addition, many of the steps for the
implementation of such a program in the U.S., as laid out in this newly
available document, are currently being promoted and implemented as part
of the government’s response to the current coronavirus (Covid-19)
crisis. This likely due to the fact that many members of this same body
have considerable overlap with the taskforces and advisors currently
guiding the government’s plans to “re-open the economy” and efforts to
use technology to respond to the current crisis.
The FOIA document, obtained by the
Electronic Privacy Information Center (EPIC), was produced by a
little-known U.S. government organization called the National Security
Commission on Artificial Intelligence (NSCAI). It was created by
the 2018 National Defense Authorization Act (NDAA) and its official
purpose is “to consider the methods and means necessary to advance the
development of artificial intelligence (AI), machine learning, and
associated technologies to comprehensively address the national security
and defense needs of the United States.”
The NSCAI is a key part of the government’s response to what is often referred to as the coming “fourth industrial revolution,”
which has been described as “a revolution characterized by
discontinuous technological development in areas like artificial
intelligence (AI), big data, fifth-generation telecommunications
networking (5G), nanotechnology and biotechnology, robotics, the Internet of Things (IoT), and quantum computing.”
However, their main focus is ensuring that “the United States … maintain a technological advantage
in artificial intelligence, machine learning, and other associated
technologies related to national security and defense.” The vice-chair
of NSCAI, Robert Work – former Deputy Secretary of Defense and senior fellow at the hawkish Center for a New American Security (CNAS), described the commission’s purpose as determining “how the U.S. national security apparatus should approach artificial intelligence, including a focus on how the government can work with industry to compete with China’s ‘civil-military fusion’ concept.”
The recently released NSCAI document is a May 2019 presentation entitled “Chinese Tech Landscape Overview.”
Throughout the presentation, the NSCAI promotes the overhaul of the
U.S. economy and way of life as necessary for allowing the U.S. to
ensure it holds a considerable technological advantage over China, as
losing this advantage is currently deemed a major “national security”
issue by the U.S. national security apparatus. This concern about
maintaining a technological advantage can be seen in several other U.S.
military documents and think tank reports, several of whichhave warnedthat the U.S.’ technological advantage is quickly eroding.
lareviewofbooks | The past two decades have brought two interrelated and disturbing
developments in the technopolitics of US militarism. The first is the
fallacious claim for precision and accuracy in the United States’s
counterterrorism program, particularly for targeted assassinations. The
second is growing investment in the further automation of these same
operations, as exemplified by US Department of Defense Algorithmic
Warfare Cross-Functional Team, more commonly known as Project Maven.
Artificial intelligence is now widely assumed to be something, some thing,
of great power and inevitability. Much of my work is devoted to trying
to demystify the signifier of AI, which is actually a cover term for a
range of technologies and techniques of data processing and analysis,
based on the adjustment of relevant parameters according to either
internally or externally generated feedback
Some take AI developers’ admission that so-called “deep-learning”
algorithms are beyond human understanding to mean that there are now
forms of intelligence superior to the human. But an alternative
explanation is that these algorithms are in fact elaborations of pattern
analysis that are not based on significance (or learning) in the human
sense, but rather on computationally detectable correlations
that, however meaningless, eventually produce results that are again
legible to humans. From training data to the assessment of results, it
is humans who inform the input and evaluate the output of the
algorithmic system’s operations.
When we hear calls for greater military investments in AI, we should
remember that the United States is the overwhelmingly dominant global
military power. The US “defense” budget, now over $700 billion, exceeds
that of the next eight most heavily armed countries in the world
combined (including both China and Russia). The US maintains nearly 800
military bases around the world, in seventy countries. And yet a
discourse of US vulnerability continues, not only in the form of the
so-called war on terror, but also more recently in the formof a new arms race among the US, China and Russia, focused on artificial intelligence.
The problem for which algorithmic warfare is the imagined solution
was described in the early 19th century by Prussian military theorist
Carl von Clausewitz, and subsequently became known as the “fog of war.”
That phrase gained wider popular recognition as the title of director
Errol Morris’s 2003 documentary about the life and times of former US
Defense Secretary Robert McNamara. In the film, McNamara reflects on the
chaos of US operations in Vietnam. The chaos made one thing clear:
reliance on uniforms that signal the difference between “us” and “them”
marked the limits of the logics of modern warfighting, as well as of
efforts to limit war’s injuries.
Has Generative AI Already Peaked?
-
This paper is discussed in the video:
Vishaal Udandarao, Ameya Prabhu, Adhiraj Ghosh, et al., No "Zero-Shot"
Without Exponential Data: Pretraining Conce...
Citizenship, Criticism, and Communism
-
In the 1940s and ’50s, Americans engaged in an intense debate over the
content of school textbooks, particularly social studies texts. Fears of
communism a...
A Foundation of Joy
-
Two years and I've lost count of how many times my eye has been operated
on, either beating the fuck out of the tumor, or reattaching that slippery
eel ...
April Three
-
4/3
43
When 1 = A and 26 = Z
March = 43
What day?
4 to the power of 3 is 64
64th day is March 5
My birthday
March also has 5 letters.
4 x 3 = 12
...
Return of the Magi
-
Lately, the Holy Spirit is in the air. Emotional energy is swirling out of
the earth.I can feel it bubbling up, effervescing and evaporating around
us, s...
New Travels
-
Haven’t published on the Blog in quite a while. I at least part have been
immersed in the area of writing books. My focus is on Science Fiction an
Historic...
Covid-19 Preys Upon The Elderly And The Obese
-
sciencemag | This spring, after days of flulike symptoms and fever, a man
arrived at the emergency room at the University of Vermont Medical Center.
He ...
 You will find more infographics at Statista
You will find more infographics at Statista