Nature | Recently, advances in wearable technologies, data science and machine learning have begun to transform evidence-based medicine, offering a tantalizing glimpse into a future of next-generation ‘deep’ medicine. Despite stunning advances in basic science and technology, clinical translations in major areas of medicine are lagging. While the COVID-19 pandemic exposed inherent systemic limitations of the clinical trial landscape, it also spurred some positive changes, including new trial designs and a shift toward a more patient-centric and intuitive evidence-generation system. In this Perspective, I share my heuristic vision of the future of clinical trials and evidence-based medicine.
Main
The last 30 years have witnessed breathtaking, unparalleled advancements in scientific research—from a better understanding of the pathophysiology of basic disease processes and unraveling the cellular machinery at atomic resolution to developing therapies that alter the course and outcome of diseases in all areas of medicine. Moreover, exponential gains in genomics, immunology, proteomics, metabolomics, gut microbiomes, epigenetics and virology in parallel with big data science, computational biology and artificial intelligence (AI) have propelled these advances. In addition, the dawn of CRISPR–Cas9 technologies has opened a tantalizing array of opportunities in personalized medicine.
Despite these advances, their rapid translation from bench to bedside is lagging in most areas of medicine and clinical research remains outpaced. The drug development and clinical trial landscape continues to be expensive for all stakeholders, with a very high failure rate. In particular, the attrition rate for early-stage developmental therapeutics is quite high, as more than two-thirds of compounds succumb in the ‘valley of death’ between bench and bedside1,2. To bring a drug successfully through all phases of drug development into the clinic costs more than 1.5–2.5 billion dollars (refs. 3, 4). This, combined with the inherent inefficiencies and deficiencies that plague the healthcare system, is leading to a crisis in clinical research. Therefore, innovative strategies are needed to engage patients and generate the necessary evidence to propel new advances into the clinic, so that they may improve public health. To achieve this, traditional clinical research models should make way for avant-garde ideas and trial designs.
Before the COVID-19 pandemic, the conduct of clinical research had remained almost unchanged for 30 years and some of the trial conduct norms and rules, although archaic, were unquestioned. The pandemic exposed many of the inherent systemic limitations in the conduct of trials5 and forced the clinical trial research enterprise to reevaluate all processes—it has therefore disrupted, catalyzed and accelerated innovation in this domain6,7. The lessons learned should help researchers to design and implement next-generation ‘patient-centric’ clinical trials.
Chronic diseases continue to impact millions of lives and cause major financial strain to society8, but research is hampered by the fact that most of the data reside in data silos. The subspecialization of the clinical profession has led to silos within and among specialties; every major disease area seems to work completely independently. However, the best clinical care is provided in a multidisciplinary manner with all relevant information available and accessible. Better clinical research should harness the knowledge gained from each of the specialties to achieve a collaborative model enabling multidisciplinary, high-quality care and continued innovation in medicine. Because many disciplines in medicine view the same diseases differently—for example, infectious disease specialists view COVID-19 as a viral disease while cardiology experts view it as an inflammatory one—cross-discipline approaches will need to respect the approaches of other disciplines. Although a single model may not be appropriate for all diseases, cross-disciplinary collaboration will make the system more efficient to generate the best evidence.
Over the next decade, the application of machine learning, deep neural networks and multimodal biomedical AI is poised to reinvigorate clinical research from all angles, including drug discovery, image interpretation, streamlining electronic health records, improving workflow and, over time, advancing public health (Fig. 1). In addition, innovations in wearables, sensor technology and Internet of Medical Things (IoMT) architectures offer many opportunities (and challenges) to acquire data9. In this Perspective, I share my heuristic vision of the future of clinical trials and evidence generation and deliberate on the main areas that need improvement in the domains of clinical trial design, clinical trial conduct and evidence generation.
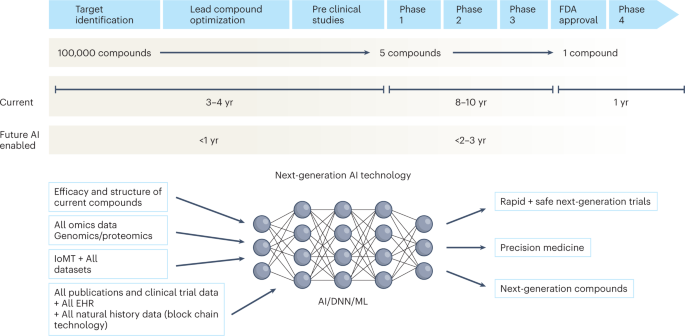
The figure represents the timeline from drug discovery to first-in-human phase 1 trials and ultimately FDA approval. Phase 4 studies occur after FDA approval and can go on for several years. There is an urgent need to reinvigorate clinical trials through drug discovery, interpreting imaging, streamlining electronic health records, and improving workflow, over time advancing public health. AI can aid in many of these aspects in all stages of drug development. DNN, deep neural network; EHR, electronic health records; IoMT, internet of medical things; ML, machine learning.
Clinical trial design
Trial design is one of the most important steps in clinical research—better protocol designs lead to better clinical trial conduct and faster ‘go/no-go’ decisions. Moreover, losses from poorly designed, failed trials are not only financial but also societal.
Challenges with randomized controlled trials
Randomized controlled trials (RCTs) have been the gold standard for evidence generation across all areas of medicine, as they allow unbiased estimates of treatment effect without confounders. Ideally, every medical treatment or intervention should be tested via a well-powered and well-controlled RCT. However, conducting RCTs is not always feasible owing to challenges in generating evidence in a timely manner, cost, design on narrow populations precluding generalizability, ethical barriers and the time taken to conduct these trials. By the time they are completed and published, RCTs become quickly outdated and, in some cases, irrelevant to the current context. In the field of cardiology alone, 30,000 RCTs have not been completed owing to recruitment challenges10. Moreover, trials are being designed in isolation and within silos, with many clinical questions remaining unanswered. Thus, traditional trial design paradigms must adapt to contemporary rapid advances in genomics, immunology and precision medicine11.